
Energy Management Advanced Analytics
i-EM is a leading, independent, global company, providing the best and fastest
digital decision support services to the energy ecosystem



our costumers



Cognitive Energy Services
From data acquisition to support the best decision taking, using Machine Learning, Big Data and Satellite data knowledge

Our presence in the world
20 years of experience in providing cognitive energy services around the world.




Our solutions for the energy management

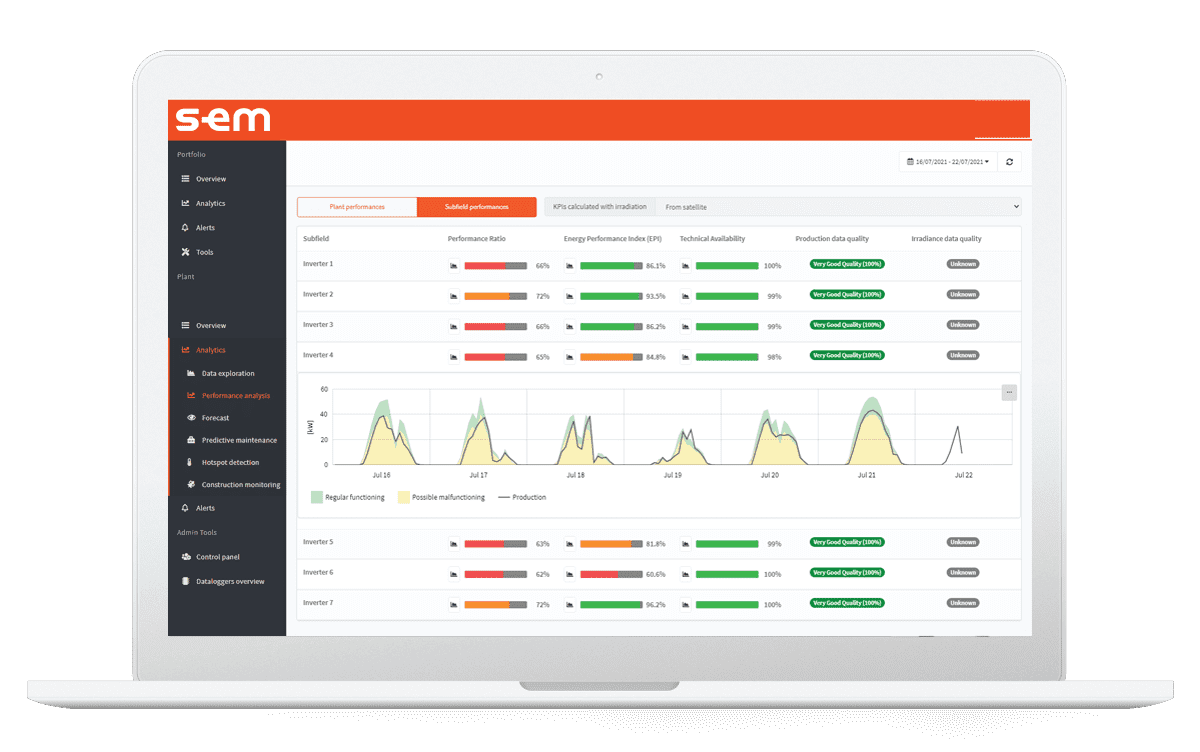
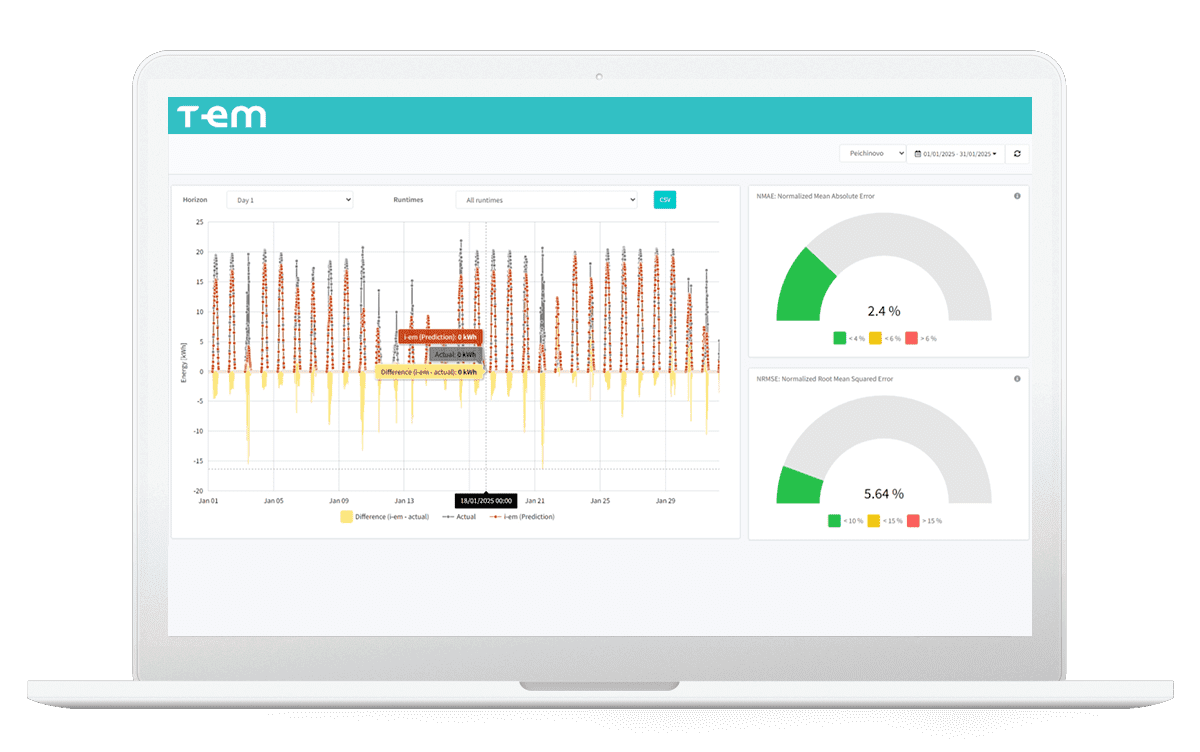
S-EM - Solar Energy Management
Get the best value from your solar asset data
Explore our Success Stories
Do you want to see what our clients have said after experiencing our solutions and services?
Check out some success stories to learn more about their positive experiences.

Big Data and Predictive Maintenance in PV
Enel Green Power
In the Predictive Maintenance, Machine Learning is a winning approach only if there is a balance between the various skills: the experience of i-EM data analysis and that of industry experts (e.g., O&M operators), to extract value and knowledge from information.

Regional Wind Forecast
Terna
i-EM forecasts help our systems for managing the stability of the grid, with respect to the unpredictability of the wind resource fed into the grid.

Hydro Plants Predictive Maintenance
Enel Green Power
We received benefits from i-EM monitoring platform and from their statistical analysis and after a first application on 5 plants in Italy, we decided to expand this digitalization on other hydro plants worldwide.
Proudly collaborating with







News & Blog
Stay up-to-date with our latest news and events dedicated to energy management.

Digital Innovation and Energy Transition: i-EM at the AGICI Renewables Conference
Milan, October 10, 2025 – Digital innovation took center stage at AGICI’s Renewables Observatory conference, “The Cost...

i-EM at EU PVSEC 2025: Spotlight on Solar Energy Resources and Next-Generation Forecasting
i-EM is at the forefront of data-driven solutions for renewable energy with extensive expertise in advanced solar...

i-EM at EM-POWER 2025: Innovations For the Future of Energy Management
i-EM is pleased to announce its participation in EM-Power Europe 2025, the international exhibition dedicated to...
Get in Touch
If you would like to learn more about us, to ask for any information or get further details about our solutions write to us.