

Data analysis second step: data acquisition
The road so far
So, you have your goal well set in mind.
Now, the next step is to get some data to fulfil your dreams.
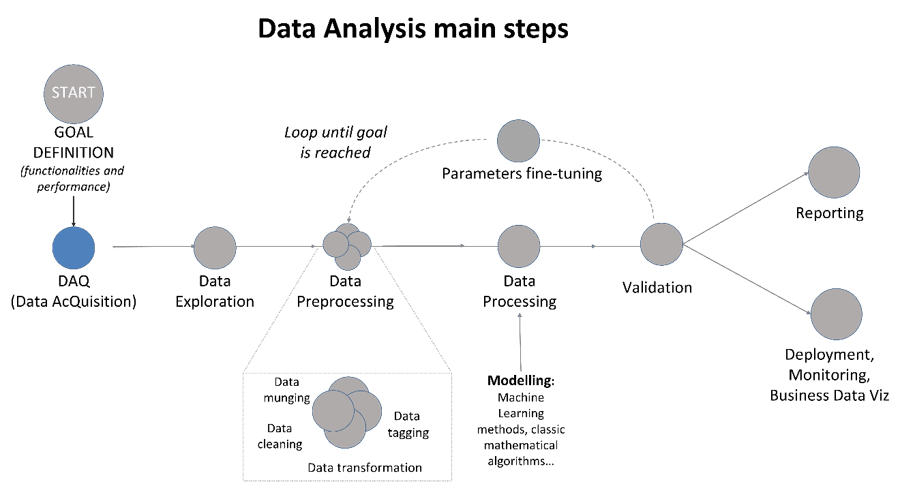
Figure 1: Data Analysis main steps.
The road ahead
The data acquisition (DAQ) is the first step, and it should be very straightforward: there is no complexity, you just have to look for data and store them somewhere. What can go wrong? Sadly, the answer is: a lot of things; for starting, you can wonder almost endlessly in a labyrinth of websites, internal storage systems, cloud areas or massive excel files and never see the light again. Then, the data format could be unknown to you, wasting additional time. Finally, there could be size limits or regulatory constraint to the use of your data. Thus, while we expect that the data acquisition step (and storing) is very fast and clean, it can be a real nightmare, both from a time and an effectiveness point of view. Here, also, you need to focus on your goal and balance the time you need to acquire all the data available in the world that could possibly be useful, and the bare necessity. For example, you can see it in this plot from a coursera lesson, comparing expectation and harsh reality in a machine learning (ML) effort allocation.
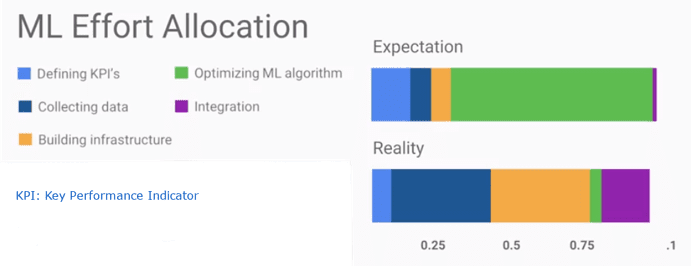
Figure 2: Machine Learning (ML) Effort Allocation. Ref.: How google does machine learning“, coursera.
So, DAQ is not for free and you learn it the hard way (you’ll be fine, with time, I guess…). BUT! Have no fear, some questions can help you to not lose the way (Behold! I also added a real-world example on the bottom):
- What kind of data do you need for your data analysis? That is, do make a list of interesting variables.
a) Do I have all the variables I need? Do I need more? Can I drop some? - How many data do you need for your data analysis?
a) Is my dataset size statistically significant enough to describe the underlining physics (we’ll call it: the “meat”)?
b) Is my dataset time-interval long enough to describe the underlining time-related specificities? - Data characteristics: Which is the spatial resolution needed? Which is the time resolution needed?
- For the sake of replicability and clearness, report down how you get the data: what is the data source? How can I access it again? Describe time-extension, kind of data, source-entity of data.
Lesson Learned becomes tip and tricks!
- A. Estimate size of raw data (the V-Volume of the Big Data 5Vs)
a. Volume greater than 1 tera (-> Big Data approach). what kind of tools can I use to cope with Big Data specificities (ex: tools as Rscale, formats as parquet or hdf5, do I acquire data directly from cloud…)?
b. Volume (very) smaller than 1 tera (-> No strict need for Big Data approach) what kind of tools can I use to cope with «small» data specificities (ex: formats as parquet or hdf5, do I acquire data directly from cloud…)? - B. Create a skimmed dataset where to perform preliminary tests:
• How much time do I need to acquire skimmed data? (in this way, you can extrapolate an estimation for the complete dataset)
• How much time do I need to run simple algorithm over skimmed data? (in this way, you can extrapolate an estimation for the complete dataset)
C. Tools: get the adequate tool for you goal.
a. Excel can be tricky to use for large size of data, let’s say 1 million rows.
D. Time-related tip and tricks: What are the time attributes? Check carefully the time-zones: for example, in the solar world, an irradiance value at 12:00 Central European Time (CET) should be very very different from 12:00 at New York Time, that is almost sunset in Europe).
E. Format: maybe you are using a csv, or an old excel file. IS the separator a “comma”, or a “semicolon”?
F. Language: maybe you are working with Spanish-talking people. Did they send to you some funny file where letters like “ñ” are present? How do you cope with that?
No rocket-science here, but some simple advice to possible reduce timewasting.
Real world example

For the curious costumer
At i-EM S.r.l., we think that a long journey starts from a single and smart step; also, we know that the devil is in the details, and a good procedure can help to take them into account. Try us!
For the keen reader
Some further readings I found interesting (not so much as my post, sadly…)
Author

Fabrizio Ruffini, PhD
Senior Data Scientist at i-EM



